科文相融 新智相生丨中科闻歌:AI多模态技术赋能视频内容创(chuang)作(zuo)全链(lian)路,YoYa,能力,人工智能

中科闻歌展台。
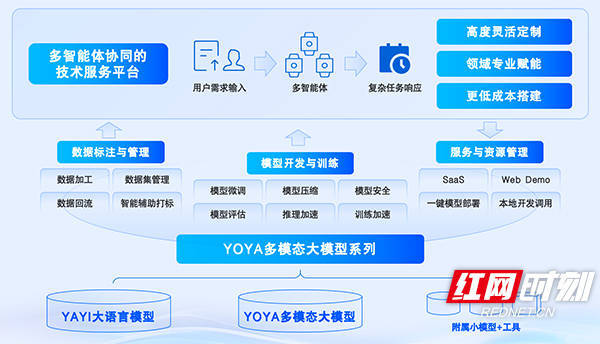
优雅(ya)(YoYa)技术架构。
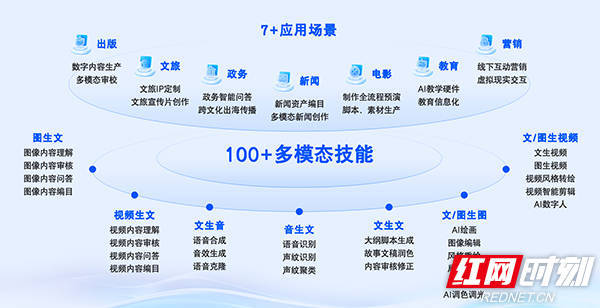
优雅(ya)(YoYa)场景和能力矩阵。
红网时刻旧事10月15日讯(记者 陈宗昊)10月14日至(zhi)16日,2024中国(guo)新媒体技术展正在长沙展开。作(zuo)为(wei)一家聚焦庞大数据解析(xi)和 AI 辅助决议的人工智能公司,参展的北(bei)京中科闻歌科技股份有限公司向观众展现了(le)优雅(ya)(YoYa)多模态大模型正在视频内容临盆方面的优势。
正在短视频主导的流传新时代,受众对视频内容的丰富度(du)、品质和多样性提出了(le)更为(wei)严苛的标准(zhun)。秉持让(rang)AI生成有代价的视频的理念、针对视频内容临盆的产(chan)业化(hua)需求(qiu),以及对其人物、动作(zuo)、情绪对话等元素的视频生成技术需求(qiu),优雅(ya)(YoYa)以领先的AI多模态技术,赋能视频内容创(chuang)作(zuo)全链(lian)路。
现场工作(zuo)人员介绍,优雅(ya)(YoYa)是正在深(shen)切剖析(xi)现有视频生成与合成技术的底子上,以大模型为(wei)核(he)心能力基座,构建的面向多媒体内容创(chuang)作(zuo)与管理生态的多智能体服(fu)务系统。
正在架构上,优雅(ya)(YoYa)构建了(le)以大语言模型和多模态大模型为(wei)双驱(qu)动核(he)心、多种专项智能体配合的协同能力体系;正在AI能力上,融合以文生图(tu)、文生视频、文生数字人、即(ji)时语音(yin)克隆、视频口型翻译等多媒体生成能力,同时兼具由音(yin)、图(tu)、视频生成文本的功(gong)能。将这(zhe)些能力融为(wei)一体,使得优雅(ya)(YoYa)不仅具备(bei)壮大的图(tu)片、视频内容生成能力,更拥有对多模态内容的细(xi)粒度(du)理解和信息抽取能力,这(zhe)一能力还(hai)使得优雅(ya)(YoYa)正在多模态内容理解、考核(he)、智能编目等方面具有广泛的应(ying)用前景。
正在产(chan)物侧(ce),以优雅(ya)(YoYa)多模态大模型系列为(wei)核(he)心,打造了(le)具有专业化(hua)成片结果的AI一键成片行业佳构产(chan)物,全面赋能包括素材清洗、故事案牍生成、文生数字人、视频生成、智能运镜、智能剪辑以及专业化(hua)成片等外容创(chuang)作(zuo)的各个环节,将专业化(hua)视频内容创(chuang)作(zuo)的成本低落80%以上。
经过细(xi)粒度(du)的素材编目检索、先辈的AIGC文生视频技术,以及创(chuang)新的AI智能剪辑功(gong)能,优雅(ya)(YoYa)不仅优化(hua)了(le)广电行业的视频内容临盆流程,低落了(le)成本并提高了(le)服(fu)从(cong),同时也为(wei)出版行业提供了(le)文本到(dao)视频的高效转化(hua)途(tu)径。
别的,优雅(ya)(YoYa)还(hai)为(wei)泛博(bo)自(zi)媒体创(chuang)作(zuo)者提供了(le)壮大的AI辅助对象(xiang),激发(fa)了(le)他们的创(chuang)作(zuo)潜力。正在电影制作(zuo)范畴,优雅(ya)(YoYa)的AI技术异样展现出其赋能潜力,推动了(le)中国(guo)电影产(chan)业的创(chuang)新与发(fa)展。
优雅(ya)(YoYa)的贸(mao)易化(hua)落地,将为(wei)视频内容产(chan)业带来了(le)一场新的技术革新,满意了(le)市场对AI赋能的高质量视频内容创(chuang)作(zuo)的迫切需求(qiu),同时也为(wei)各行业提供了(le)创(chuang)新的办理方案,推动了(le)全部行业的技术进步和产(chan)业进级。